학교 머신러닝 과목 과제로 https://archive.ics.uci.edu/ml/datasets.php
UCI Machine Learning Repository: Data Sets
Multivariate, Sequential, Time-Series, Domain-Theory
archive.ics.uci.edu
이 곳에 있는 데이터 set 중에서 원하는 것을 골라 feature engineering 을 통해 유의미한 분석을 해내라는 과제가 나왔다.
필자는 youtube spam data를 선택했다. 재밌게 해볼수 있을 것 같아서~
머신러닝 관련 프로그램 다뤄본것도 거의 1년.. 다되갈 정도로 오래됐고, 자연어 처리 관련 부분도 처음 공부하는 것이기 때문에 블로그에 정리하면서 과제를 조금씩 진행하려고 한다.
우선 csv같은 테이블 형식 데이터를 쉽게 다루기 위해서는 pandas라는 라이브러리를 활용하면 좋다.
설치는 다른 블로그에 정리가 잘 되어있을테니.. 안깔으신 분들은 참고하시면 될 것 같다.
판다스는 dataframe이라는 객체로 데이터를 받아온다.
다음과 같은 단 2~3줄이면 csv를 dataframe으로 변형해서 가져오는 것이 가능하다.
import pandas as pd
data = pd.read_csv("파일저장경로")
마지막 data는 주피터 노트북에서 전체 dataframe을 확인하려고 넣은 것이다.

우리는 어떤 댓글이 스팸인지에만 관심이 있지, ID라던지 author date는 고려에 전혀 영향을 끼치지 않는 요소이다.
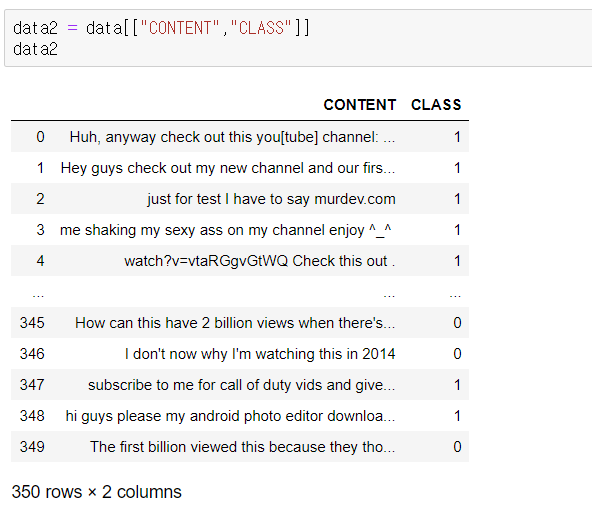
따라서 content와 class 만의 데이터를 가져오면 되므로, dataframe을 변형해준다.
data2 = data[["CONTENT","CLASS"]]
data2
마지막으로 문장들이 전부 넣어진 리스트를 만들기 위해 다음처럼 코드를 실행시켰더니, 왜인지는 모르겠지만 \ufeff 문자열이 자꾸 문장들 뒤에 다음과 같이 붙었다.
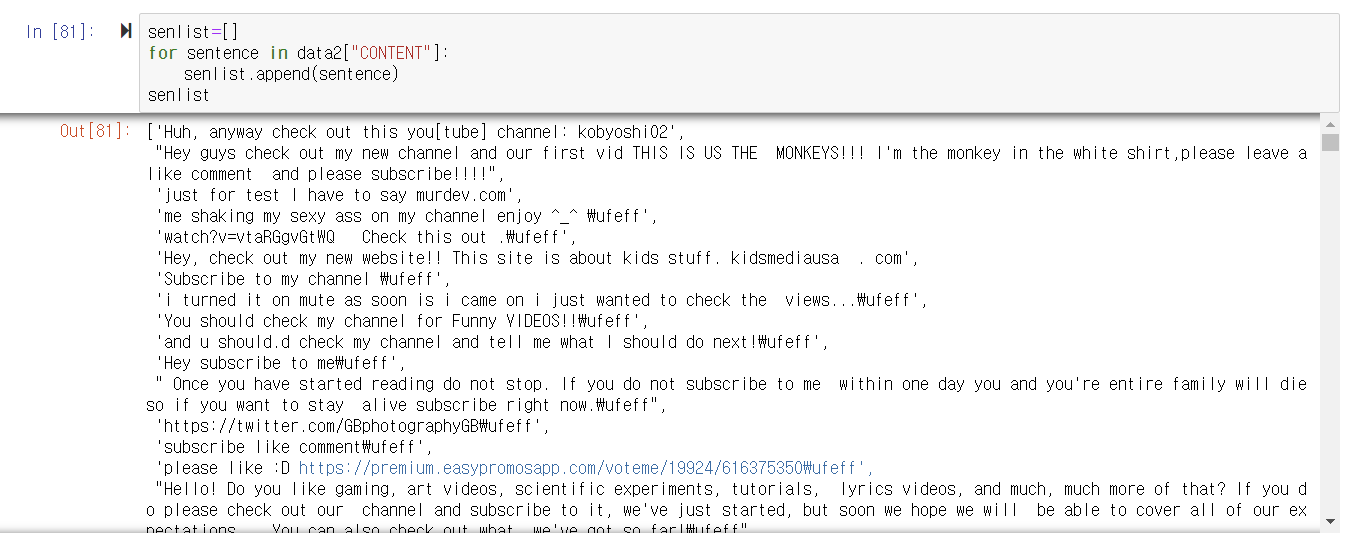
utf-8 인코딩이니 뭐니 여러 이야기들이 인터넷에 많이 떠돌던데, 여러개 시도해 봤는데 내 데이터에는 잘 안먹혔다.
그래서 python의 replace 함수를 이용해 매뉴얼하게 문장을 바꿔서 리스트에 넣어주었다.

'머신러닝' 카테고리의 다른 글
| [빅데이터] word2vec 모델 적용시키기 - 유튜브 스팸 데이터 분석해보기(2) (0) | 2020.05.26 |
|---|
